Troubleshooting
Jira Server only
Enabling the logs
Links Hierarchy writes traces in the JIRA logs. However, this feature is disabled by default and you have to explicitly authorize the plugin for that:
JIRA > Administration > System > Troubleshooting & Support > Logging and Profiling > Default Loggers > Configure:
- Package Name: com.kintosoft.jira.links
- Logging Level: DEBUG
Repeat please the test and send the relevant traces for supporting.
Keep in mind that the configuration above is automatically reset if JIRA is re-started so you have to grant the plugin to write in the JIRA logs again.
Export to Excel 404 error
Resolved from version 5.3.3
Since version 5.3.3 it is not necessary to set Jira local URL.
If you experience any problem when exporting to Excel after updating to version 5.3.3, please clear the browser cache.
Description: The HTTP 404 error code is got when a hierarchy is exported to Excel
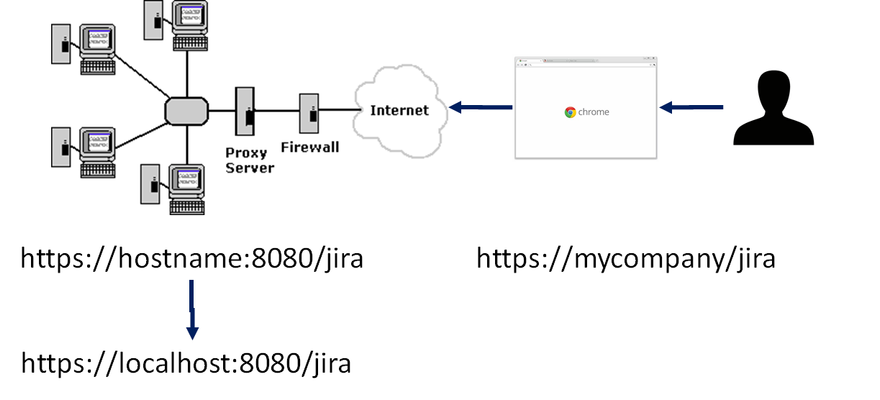
The plugin fully works out-of-the-box. However, under some network configurations, some extra configuration steps might be required. Frequently, Jira is host on some server at then corporation intranet behind a proxy server with a public URL (please see the picture below): The user types the public URL in the browser (https://mycompany/jira) which is forwarded by the proxy to the internal server hosting Jira (https://hostname:8080/jira). The plugin uses the public URL (https://mycompany/jira) to access to the Jira host (https://hostname:8080/jira) to export to Excel. This may cause 404 HTTP errors as a lot of times, the DSN used by the Jira host is not aware of the proxy (public) URL,
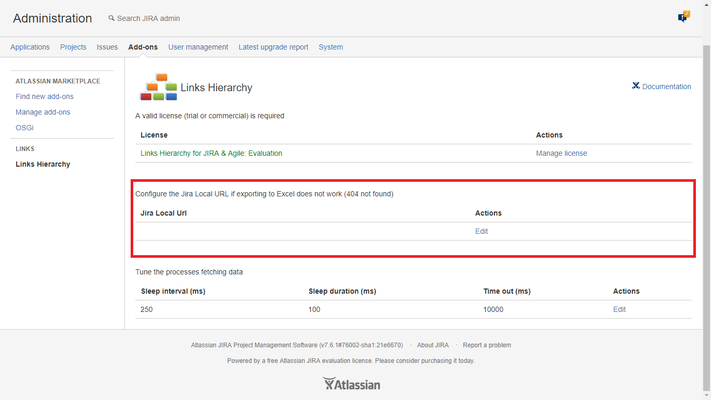
Set Jira local URL (Recommended)
In newer versions it is possible to set the Jira local URL:
Configure the Jira host DSN
Unfortunately, in earlier versions of the plugin, it is necessary to help the plugin to reach the proxy by:
- Configure the DNS used by the Jira host to resole the proxy name
- Add the proxy name and address to the /etc/hosts file
Time outs in the logs / Incomplete hierarchies / blank JQLs / CPU & Performance issues (ADVANCED)
Sometimes Links Hierarchy might require a lot of time to read all the data, this might require consuming Jira resources (CPU, Threads, RAM, etc) for a long while that might cause performance issues.
So, the app divides the job of the threads into pulses of work:
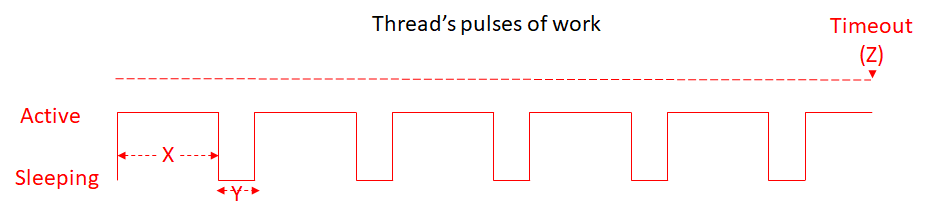
Each thread building a hierarchy works for X milliseconds and then sleeps for Y ms. If the job is not completed under a threshold (Z), the job is aborted and the thread frees.
JQLs support an additional timeout:
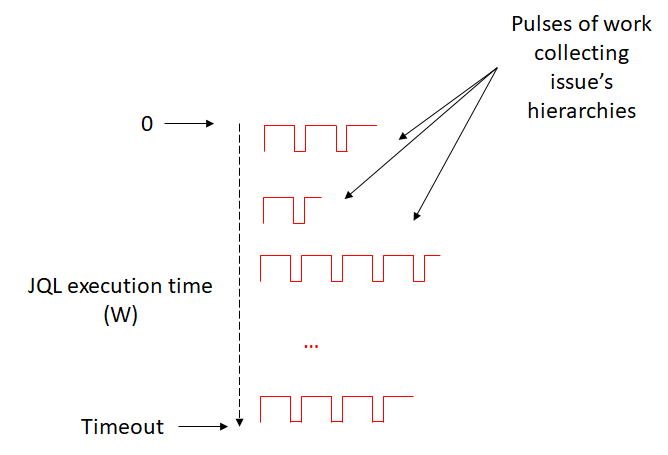
A JQL returning N issues will build N hierarchies by using pulses of work foe each root issue. This creates a sequence of pulses that might take a long while. This makes the thread might also take a lot of work (minutes) to be completed. The JQL timeout is checked every time between the start and the end of the sequences of pulses. If the timeout is reached (W), the JQL will by atomátically aborted freeing the thread. In that way, Jira administrators can avoid too long working threads.
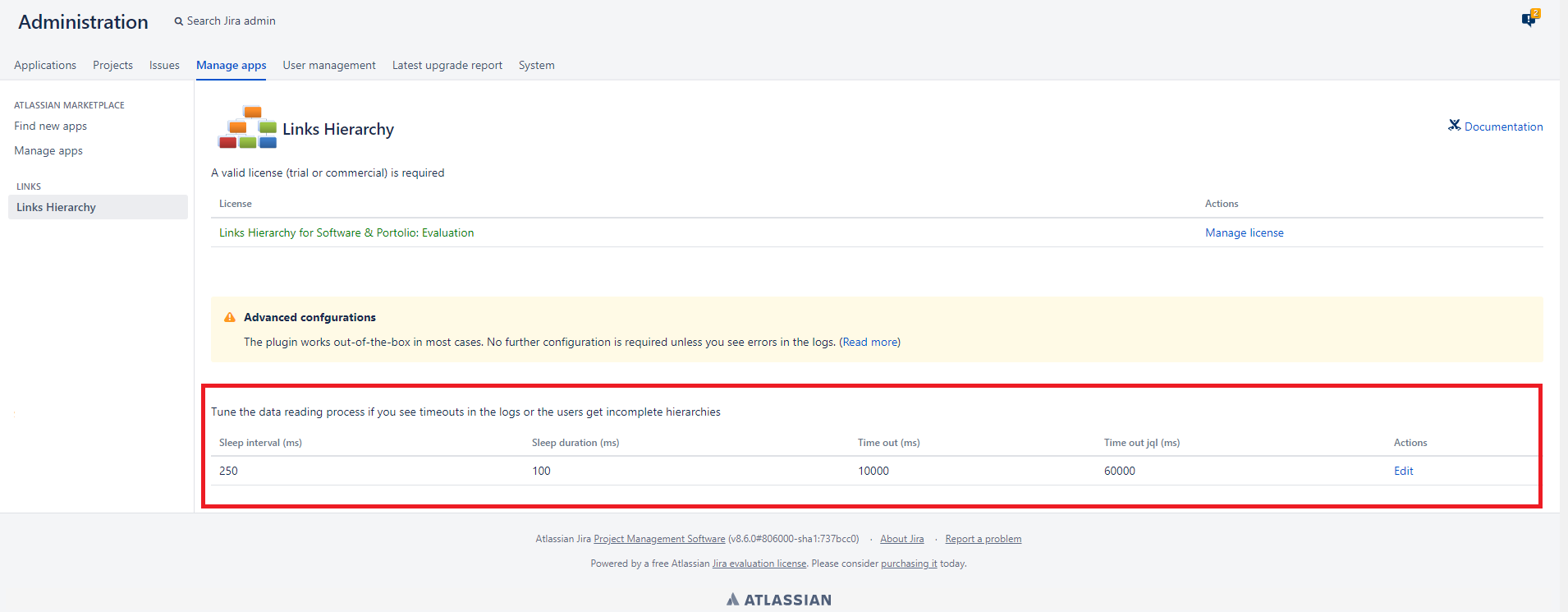
- SLEEP_INTERVAL (X): The number of milliseconds that the process will work before to sleep. The default is 250 ms.
- SLEEP_DURATION (Y): How many milliseconds the process will sleep. The default is 100 ms.
- TIMEOUT (Z): The threshold in milliseconds to get all the hierarchy data (includes sleeping time). The default is 10000 ms
- TIMEOUT_JQL (W): The threshold in milliseconds to get all the jql data (includes sleeping time). The default is 60000 ms
In other words, the process of reading data works for 250 milliseconds, then goes to sleep for 100 milliseconds in a loop. After 10 seconds the process is aborted causing incomplete hierarchies for every issue hierarchy. In addition for JQL, there is one-minute timeout to complete the work.
In the case of the jql's, if TIMEOUT_JQL is exceeded, the execution of the jql will be aborted and will return an empty set of data
The SLEEP parameters can be modified to allow the process to read data faster and the TIMEOUT for more time.
The number of free resources (threads, CPU, and RAM) on Jira are limited and shared with the rest of the apps. Of course, there is not one simple pattern for all the organizations: the default parameters are quite conservative and they work fine in most organizations, however, some hierarchies may require more time. A more aggressive approach like
- SLEEP_INTERVAL: 1000
- SLEEP_DURATION: 25
- TIMEOUT: 20000
might allow reading all the data. Depending on the number of links, users' concurrency and peaks of work, the plugin can be optimized to load more data.
If some hierarchies are not being fully loaded (time out errors in the Jia logs when the plugin traces are enabled), the Jira administrators can tune the plugin to allow reading all the data while Jira is also being monitored.
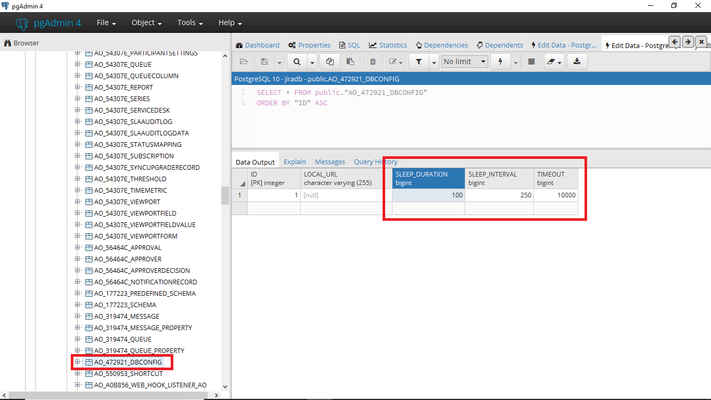
Those parameters can also be modified in the Jira database directly: