Timeouts loading data
- Pablo Beltran (Unlicensed)
- David Ortiz
Jira Server only
Hierarchies could take a long time in order to be fully built in memory at the server and they can be quite expensive in server resource terms (CPU, memory, threads…). Therefore some optimizations are supported by Links Hierarchy in the server to ensure the performance and reliability of Jira while thousand users build and view hierarchies:
There are three configurable parameters to tune links hierarchy in order to adapt it to each customer's environment. Despite the default configuration is very conservative, it works well in most of the cases.
Some knowledge about OS threads is required for next section
In Jira, every call to the server from a client it is attended by a thread. Threads are a limited resource in the Operating System and mainly in the Java Virtual Machine (JVM), therefore, it is important do not block threads for a long time to avoid Jira become unresponsive. Every time that a hierarchy ask for data to the server, a thread is consumed form the JVM's threads pool.
Furthermore, hierarchies' data is fetched recursively by the app. Recursivity is very powerful feature supported by the Java language, however, it could consume a lot of CPU.
Consequently, Links Hierarchy supports some thresholds and behaviors to work in a collaborative environment like Jira by limiting customers access to the JVM resources.
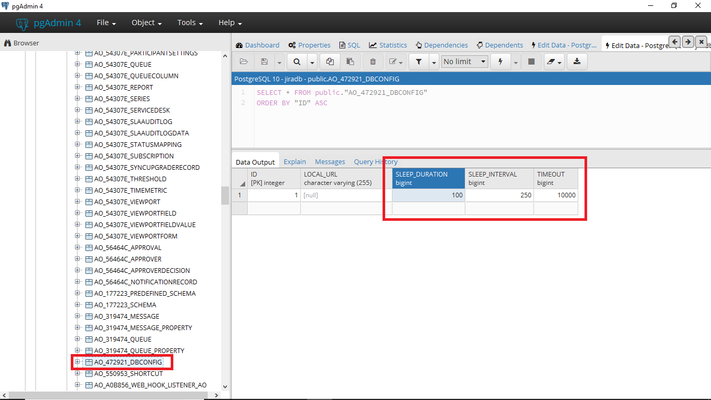
- Limiting the overall time to fetch all the data. By default, Links Hierarchy supports a 10.000 milliseconds timeout. When the timeout is achieved, the process fetching data is aborted and the thread released.
- Sharing the thread with others. Links Hierarchy forces the thread to sleep for some time (100 milliseconds) every interval (250 milliseconds). When a thread is sleeping, other process in the JVM (Jira) can reuse it. In other words, threads are used in a collaborative way.
All those parameters above can be configured by the JIra administrators. Click on the Troubleshooting link at the bottom of the Links Hierarchy configuration page:
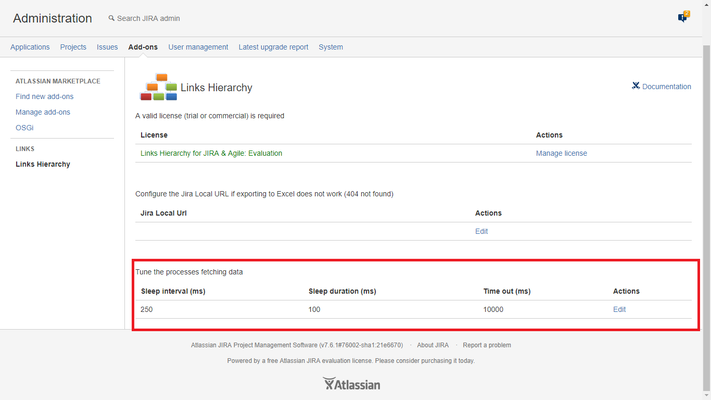
Depending of the available hardware (RAM, CPU), amount of users, peaks of activity and the rest of the environment like the amount of issues and links and other third party plugins installed, etc.The Jira administrators might want to set a more less conservative approach. I.e
- Timeout: 25.000 ms
- Sleep interval: 2000 ms
- Sleep duration: 50 ms
Those values are read in real-time, so re-.enabling the plugin is not required.
Those parameters can also be modified in the Jira database directly: